Research Update 01: Getting familiar with text-to-sql datasets
Posted on Oct 7, 2024 by Felipe Aníbal
Last updated on Oct 7th, 2024
I began the research project trying to familiarize myself with text-to-sql. This meant reading many articles to better understand the problem at hand and downloading and exploring the benchmark datasets that are used in most papers.
Material Studied
I learned a lot in the past weeks from articles recommended by Karina Fróes, Diego Lopes and prof. Kelly Braghetto. Some articles gave me a better view of text-to-sql in general and others gave ideas about data augmentation more specifically.
A survey on deep learning approaches for text-to-SQL - George Katsogiannis-Meimarakis - Georgia Koutrika1
This article1 was a fantastic way to start the research. It offers a very complete and up-to-date overview of text-to-sql translation. The article starts by defining what is the text-to-sql problem: "Given a natural language query (NLQ) on a Relational Database (RDB) with a specific schema, produce a SQL query equivalent in meaning, which is valid for the said RDB and that when executed will return results that match the user’s intent." Then it proceeds to explain what are some of the challenges of building robust models for this task - these were discussed briefly in the last Research Update.
A very useful part of this article was the third section, were the authors introduce the Cross-Domain text-to-sql datasets and the evaluation metrics for the problem. Here they explain what are Spider2 and BIRD3 - two datasets widely used to train and evaluate text-to-sql models. The creation of these datasets allowed researchers to have a standardized data on which to test their models and a data collection on which to train new models, fuelling great advances in the field.
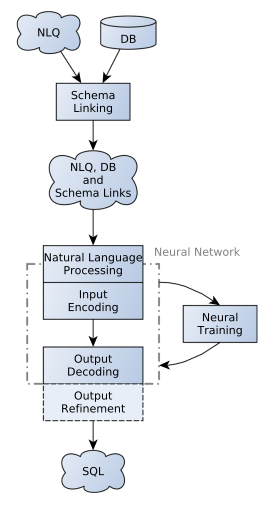
Finally, this article also elucidated the components that make up a NL-to-SQL model. The figure below illustrates the general idea.
mRAT-SQL+GAP: A Portuguese Text-to-SQL Transformer - Marcelo Archanjo José and Fabio Gagliardi Cozman4
In this article4, Fabio Cozman and Marcelo Archanjo translate one of the benchmark datasets mentioned above in order to make SQL queries from questions in portuguese. Besides translating the dataset they adapt the code from an existing model to allow multilingual text-to-sql.
An important finding of the article was that the model performed better when it was trained with the original and the translated versions of the database than when it was trained only with the translated version. This gives an important insight into future multilingual text-to-sql models.
For the experiments, the authors use a model called RAT-SQL+GAP and adapt it to be multilingual. The "GAP" in the name stands for Generation-Augmented pre-training. This is a topic that I'll look at in the future to understand how they do the augmentation.
After reading this paper I downloaded the spider dataset and tried to replicate the its translation. This was great to further understand how spider is structured.
SQL-PaLM: Improved large language model adaptation for Text-to-SQL (extended)5
SQL-PaLM5 is a framework to improve text-to-SQL using LLMs. One of the highlights of the article for me was learning about how they used LLMs for data augmentation. The authors even leave the prompts used for the augmentation in the appendix of the article. With synthetic data added to the training data they improved the accuracy in 1.3%.
One of the goals for the next couple of weeks is to try those prompts to augment some example dataset.
Exploring Spider
The spider dataset is organized in three main parts: 1) the {SQL query, NL}-pairs for training, 2) the {SQL query, NL}-pairs for testing and 3) the databases and database information.
I downloaded the source code from the article of Fabio Cozman and Marcelo Archanjo4 and decided to replicate part of what they did to understand how challenging it would be to translate the benchmark dataset as this could be a first source of NL questions in portuguese. I wrote a python script to translate the natural language questions from spider using the google translator API as the authors did in the article. The way that the jsons are structured makes it easy to do the translation. It took me 12 minutes to translate every NL question on the training dataset.
One of the problems with simply translating the NL questions from the dataset is that the values on the databases are not translated. This adds a challenge to the text-to-sql model, one related to schema-linking - the process of linking the name used in the schema to the tokens of the natural language. I believe that this is one of the reasons why the model trained on both the original and the translated dataset performs better than the model trained only on the translated data-set.
As a next step I believe that training and using a model like they did in the article would help me better understand text-to-sql translation, and even evaluate different models and training datasets. But the authors estimate it would take 60 hours to train the model, so I haven't tried training yet.
Next Steps
In the next couple of weeks I plan to read more about data-augmentation for NL problems in general - not only text-to-sql. I hope to see what are the techniques available for this task and how they can be applied in text-to-sql.
I would also like to perform the first experiments in the next weeks, using some of the data augmentation techniques to expand text-to-sql databases. The first technique I would like to try is the one used in the SQL-PaLM article where they use LLMs to expand a dataset.
References
- George Katsogiannis-Meimarakis and Georgia Koutrika. 2023. A survey on deep learning approaches for text-to-SQL. The VLDB Journal 32, 4 (Jul 2023), 905–936. https://doi.org/10.1007/s00778-022-00776-8
- Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and others. 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems. https://arxiv.org/pdf/2305.03111
- Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, Dragomir Radev. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. https://arxiv.org/abs/1809.08887
- Marcelo Archanjo José, Fabio Gagliard Cozman. 2021. mRAT-SQL+GAP: A Portuguese Text-to-SQL Transformer https://arxiv.org/abs/2110.03546
- Ruoxi Sun, Sercan Ö. Arik, Alex Muzio, Lesly Miculicich, Satya Gundabathula, Pengcheng Yin, Hanjun Dai, Hootan Nakhost, Rajarishi Sinha, Zifeng Wang, Tomas Pfister. 2023. SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL (extended). https://arxiv.org/abs/2306.00739