Research Update 02: Preliminary augmentation attempts
Posted on Oct 23rd, 2024 by Felipe Aníbal
Last updated on Oct 23rd, 2024
In the past couple of weeks I studied data augmentation (DA) techniques for natural language processing (NLP) in general (not necessarily applied to text-to-sql) and a made some preliminary experiments to understand those techniques.
What data augmentation techniques are there for text?
Data augmentation had its origins in computer vision where simple transformations can be applied to the datasets while still maintaining its main characteristics. The image of a dog, for instance, can be rotated, mirrored and even changed to gray-scale while still representing a dog. That is the goal of data augmentation - to increase the diversity of the dataset while maintaining the characteristics that are relevant for the task we are working on. Another area where DA showed good results is audio processing for speech recognition. We can change speed, pitch and add noise to the audio while maintaining its characteristics.
When working with text, however, data augmentation is not so simple! As we will see, there are several ways to augment text, but it can be really challenging to make sure we have not lost important characteristics of the text, like its semantics or syntactical correctness.
Some authors1 divide DA strategies into 3 categories: paraphrasing, noising and sampling. The paraphrasing-based methods aim at modifying the text, while maintaining its semantical meaning. The goal is to create a new text, with the same information as the original. The noising-based methods try to improve the robustness of the model adding noise to it. This can happen at a character scale - changing letters in a text - or at a word scale - changing entire words. And the sampling-based methods try to learn data distributions and sample new data from it. Each of these approaches have many different implementations.
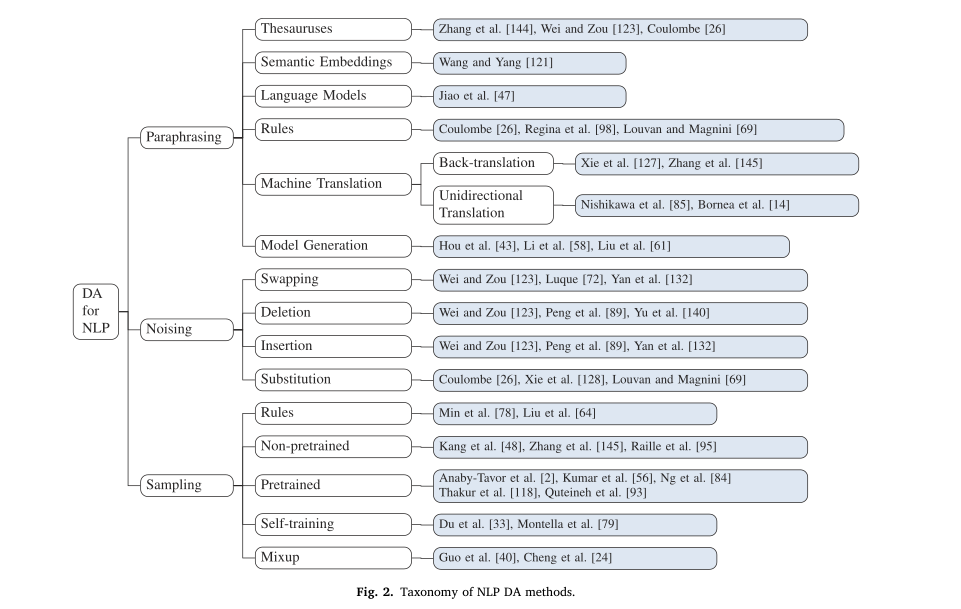
I decided to start exploring 2 paraphrasing-based methods: back-translation and language models. To start, I made naive implementations of those strategies, with the hope of gaining basic intuition and improving each implementation on the weeks to come.
Experimenting with back-translation
Back-translation means translating a text from one language to the other and then back to the original language. The idea is that translation algorithms might make slight modifications to the text while retaining its meaning. Since translation algorithms and machine translation have improved significantly in the past decades, this approach tends to produce accurate translations, but doesn't always add much diversity to the text.
To test back-translation, I made a simple implementation using google translator API from a python library called deep-translator. Since the goal of the research project is to augment data-sets in portuguese, I used sentences in portuguese, translated them to english and then translated them back to portuguese. Here are some examples of such translations:
-
Original: Quantos chefes de departamento tem mais que 56 anos?
Paraphrasis: Quantos chefes de departamento tem mais de 56 anos? -
Original: Dos colégios com menos de mil alunos, quantos têm acesso a computadores e à internet?
Paraphrasis: Das escolas com menos de mil alunos, quantas têm acesso a computadores e à internet? -
Original: Qual a média de anos de estudo das pessoas com salários acima de 50 mil dólares?
Paraphrasis: Qual é o número médio de anos de estudo para pessoas que ganham mais de US$ 50.000?
All of the phrases above have their meaning preserved when translated back to the original language, with small modifications to the way they are written. A modification that we can make to try to introduce more diversity to the new sentences is to add more intermediate languages to the translation. Here are the same sentences above, but translated from portuguese to english, from english to french, and from french back to portuguese.
-
Original: Quantos chefes de departamento tem mais que 56 anos?
Paraphrasis: Quantos chefes de departamento tem mais de 56 anos? -
Original: Dos colégios com menos de mil alunos,
quantos têm acesso a computadores e à internet?
Paraphrasis: Entre as escolas com menos de mil alunos, quantos têm acesso a computadores e à Internet? -
Original: Qual a média de anos de estudo das pessoas com salários acima de 50 mil dólares?
Paraphrasis: Qual é o número médio de anos de educação para pessoas que ganham mais de US$ 50.000?
Using more languages we seem to add more diversity to the sentences generated, but it also risks loosing precision. Notice that in the second paraphrasis of this example the translator made a grammatical error (highlighted).
Another experiment that can be done is to try different translation algorithms. In particular, for the next weeks, I would like to try large language models to perform the translations.
LLMs to augment SQL queries
The second strategy I explored for data augmentation was one described in the SQL-PaLM article 2 that I mentioned in the last research update. The authors of this paper use a Large Language Model (LLM) to generate more ground-truth SQL queries for the task of text-to-sql translation. For this experiment I used the same prompt as the authors in 3 different LLMs, but with the Natural Language question in portuguese.
Prompt Example:
You will be provided with a list of tables from a SQL database followed by a natural language query related to the database and the original SQL query answering the question. Your job is to understand the natural language queries and generate up to 3 different SQL queries using diverse commands from the original query while answering the question correctly. You need to make sure to use the same columns from the original query for the generated query. You will also generate a similarity score between the original and the generated query based on how closer they are syntactically.
Database tables schema are as follows:
CREATE TABLE head (age INTEGER)
Question: Quantos chefes de departamento têm mais de 56 anos ?
Original SQL query:
SELECT COUNT(*) FROM head WHERE age > 56
Output the generated queries and the similarity scores in a json list as follows:
[
{'sql': // generated query-1,
'similarity': // similarity score (0.0-1.0) for query-1
},
{...}
]
Llama 3.1 with 8 Billion Tokens
First I used Llama 3.1 to perform the augmentation. The advantage of using llama is that it is free. However, the larger and better Llama models (with more tokens) require a lot of computational power. So far I have only been able to test the smaller model with 8 billion tokens. Here are the prompts that this model generated:
sql: "SELECT COUNT(*) FROM head WHERE age > 56",
similarity: 1.0,
sql: "SELECT * FROM head WHERE age = 57 AND age > 56",
similarity: 0.75,
sql: "SELECT COUNT(age) AS quantidadechefes FROM head WHERE age > 56",
similarity: 0.8,
Notice that the first generated query is identical to the original, the second one does not correspond to the original NL query and the third one is correct. This means that out of 3 generated queries 1 corresponds to the ground-truth SQL.
GPT 4 mini
Llama 3.1 8B is trained with much fewer tokens than GPT4 mini. Therefore, it was expected that GPT would produce better results. Here are the queries it generated:
sql: "SELECT COUNT(age) FROM head WHERE age > 56",
similarity: 0.9
sql: "SELECT COUNT(*) FROM head WHERE age >= 57",
similarity: 0.85
sql: "SELECT SUM(CASE WHEN age > 56 THEN 1 ELSE 0 END) FROM head",
similarity: 0.75
All queries generate by GPT4 mini were correct. It is worth noting that the third query uses a dialect that is not allowed in all SQL database systems.
Gemini 1.5 Flash
Gemini Flash generate the following results:
sql: "SELECT count(*) FROM head WHERE age > 56",
similarity: 1.0
sql: "SELECT sum(CASE WHEN age > 56 THEN 1 ELSE 0 END) FROM head",
similarity: 0.6
sql: "SELECT count(age) FROM head WHERE age > 56",
similarity: 0.8
This model generated 3 correct queries as well, one of which is identical to the original.
This seems to be a very promising augmentation strategy and the bigger models seem to create better results. I would like to explore other models like BERT and see if I can use bigger versions of Llama.
Paraphrasing with NLTK
Another strategy for paraphrasing is substitution for synonyms. The idea is to substitute some of the words in a sentence for synonyms. There are multiple strategies for this substitution. Again, to start, I made a naive implementation where each word is substituted by a synonym with probability p. The program gets the synonyms from Word-Net and Open Word Net (OWM) a corpus of text that includes synonyms, antonyms and other information for each word in the dataset.
This idea produced some very good results for some sentences, but it also has many limitations. Sometimes the word substitution produces a great match. In one of the experiments the sentence "Artificial intelligence is changing the world" was changed to "Artificial intelligence is transforming the planet". This is a great result. However, in another experiment, "intelligence" was substituted by "talent" and "artificial" was substituted by "fake". This produced the sentence "Fake talent is changing the world", which completely changed the meaning of the original sentence.
Original: Artificial intelligence is changing the world.
Paraphrasis: Artificial intelligence is transforming the planet.
Paraphrasis: Fake talent is changing the world.
There are other ways to make synonym substitution that might lead to better results. One possibility is to rank the word relevance in the sentence and only substitute the less important words. If we only change the less important words, the impact of that change in the sentence meaning should be smaller. This might avoid problems like the one we had above. Another strategy is to use embeddings. This involves representing the words as numeric vectors, this way we can measure the distance between two words and rank the synonyms to find the best ones to substitute a given word. For the next couple of weeks I hope to explore these techniques further.
LLMs to augment the natural language questions
After experimenting with LLMs to augment the SQL queries I decided to try LLMs to augment the NL questions. I modified the prompt used to generate SQL queries, and changed it to generate NL questions. I gave the model the same databases as before and NL questions in portuguese.
At first I didn't specify that the new sentences generated by the model should be in portuguese. The result is that the model generated the new questions in english. The results, however, were very good!
Original: Quantos chefes de departamento tem mais que 56 anos?
Paraphrasis: How many department heads are over 56 years old?
Paraphrasis: What is the count of department heads who have ages greater than 56
Paraphrasis: How many people are in charge of a department and older than 56 years?
I then specified that the questions should be generated in portuguese. The result was that most of the questions changed the meaning of the original sentence. Here are the results (translated to english by me).
Original: Quantos chefes de departamento tem mais que 56 anos?
Paraphrasis: Quantos funcionários têm mais de 56 anos? (translation: How many employees are older than 56)
Paraphrasis: Existem funcionários com idade superior a 56 anos? (Are there employees older then 56 year old?)
Paraphrasis: Quais são as idades dos chefes que ultrapassam 56 anos? (What are the ages of employees older than 56 years old?)
I believe that the poorer results come from the fact that the Llama model is trained primarily with an english corpus. This might make the performance worse in tasks that involve other languages. This observation, however, led to a new possibility for future experiments. Since most augmentation techniques were developed based on a corpus in english, it may be a good idea to perform the augmentation in english and later translate the results back to portuguese. This would be equivalent to combining some data augmentation strategy with back-translation and could potentially produce better results.
Ideas and next steps
In the weeks to come, I hope to continue studying DA strategies for text augmentation and applying theses strategies to the context of text-to-sql. In particular, I hope to explore back-translation with LLM models, generation of the questions using texts in english and embedding substitution. I also want to study more about LLM's like BERT and see if they can be used for synonym substitution as well. More updates soon!
References
- Bohan Li, Yutai Hou, Wanxiang Che. Data augmentation approaches in natural language processing: A survey. https://arxiv.org/abs/2110.01852
- Ruoxi Sun, Sercan Ö. Arik, Alex Muzio, Lesly Miculicich, Satya Gundabathula, Pengcheng Yin, Hanjun Dai, Hootan Nakhost, Rajarishi Sinha, Zifeng Wang, Tomas Pfister. 2023. SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL (extended). https://arxiv.org/abs/2306.00739